
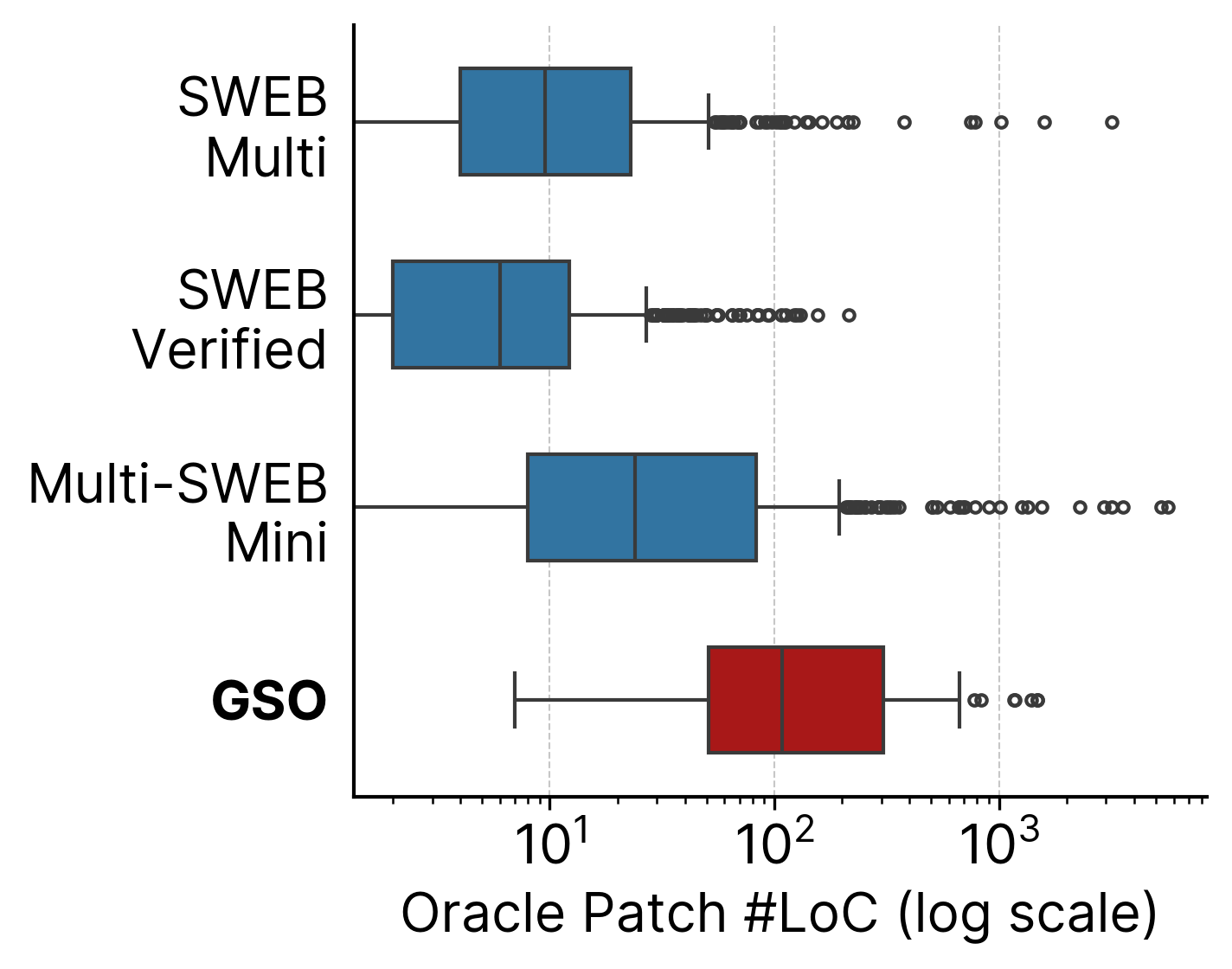
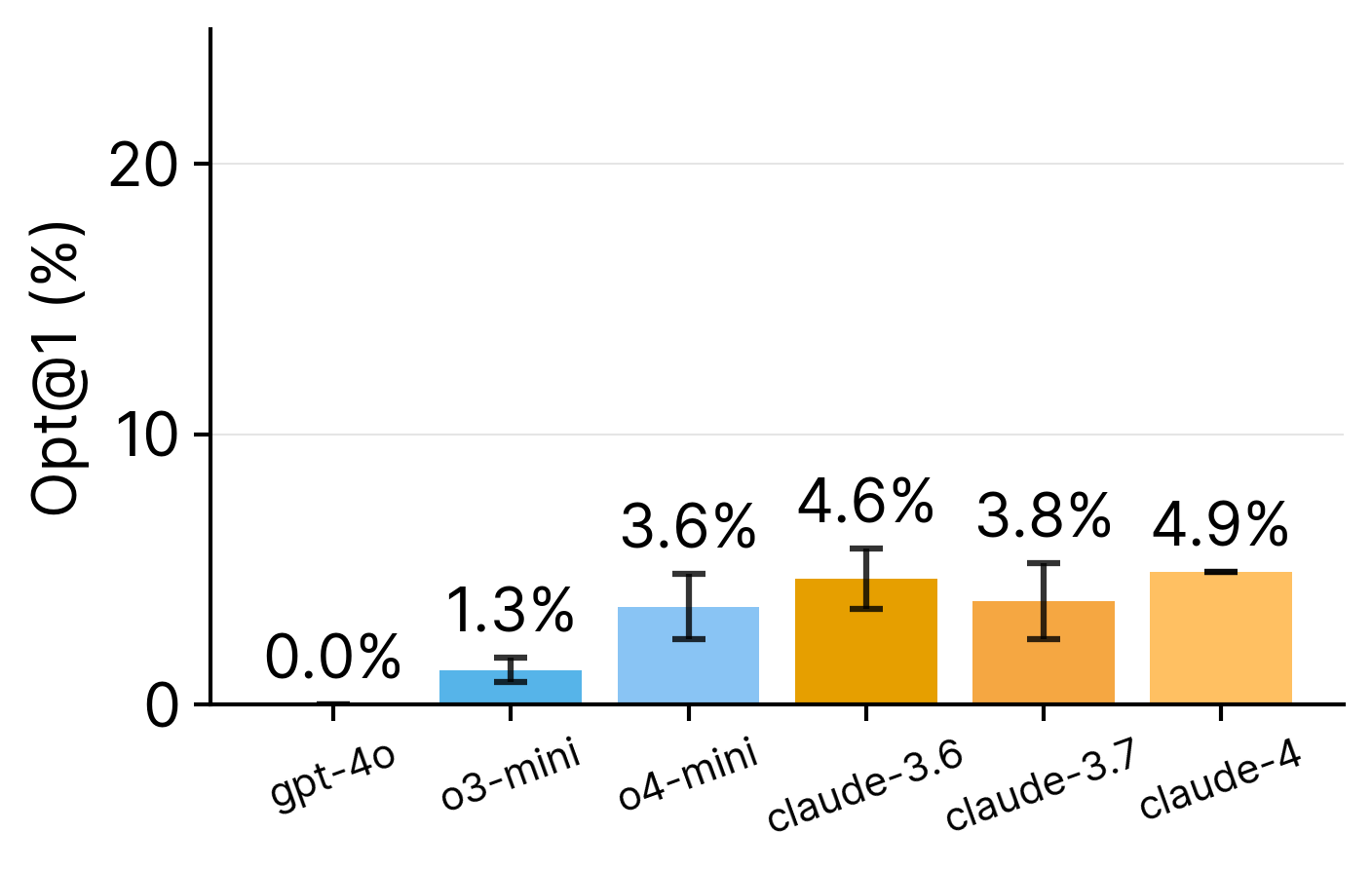
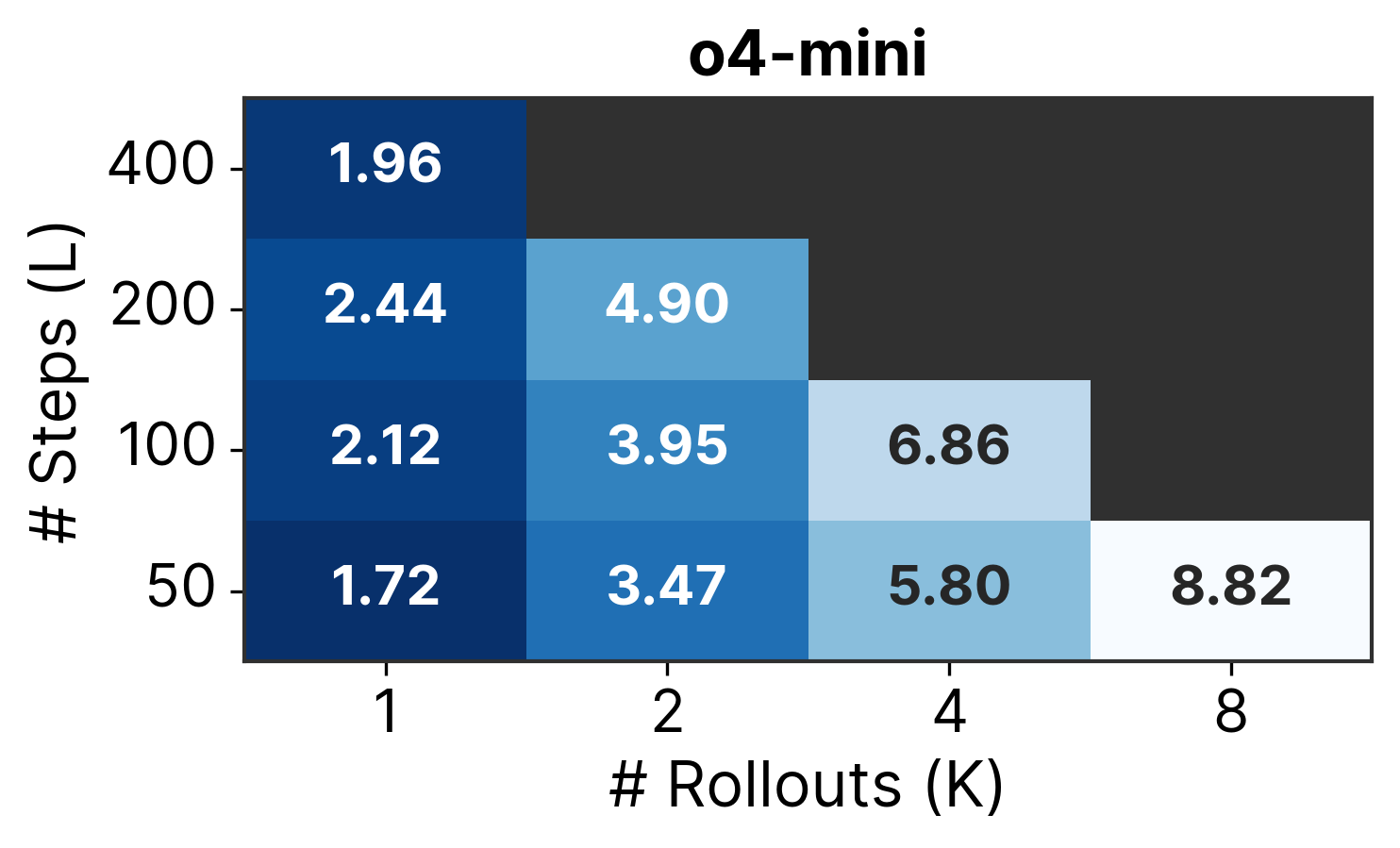
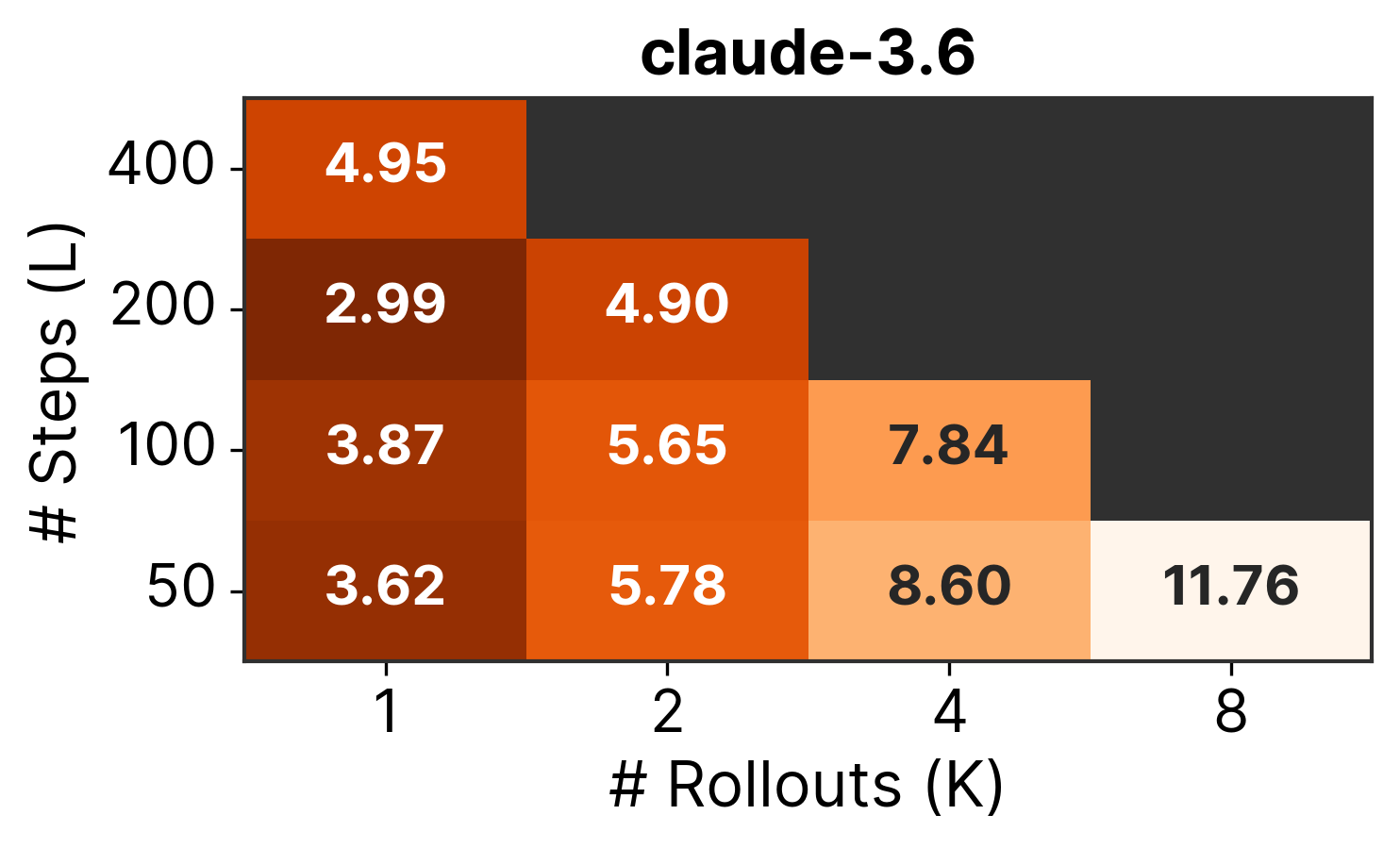
Description: Models perform best with high-level languages, with O4-Mini achieving 21% on Python tasks but dropping to 4% when C/C++ are involved.
Why it matters: Production codebases have abstraction hierarchies, and operating at inappropriate levels contributes to 25-30% of agent failures. Models either avoid necessary low-level changes or make unnecessary ones.